

C#の変数には値型と参照型との2つのタイプが存在します。
(ポインタ型というのも存在しますがよほどのことが無い限り使いませんし使うべきでないと思ってます)
「値型」は構造体(struct) や列挙型(enum) です。
int や double といった数値型は実は構造体で定義されているので値型です。
※詳しくは「C#のStringとstring、Int32とint 違いは・・・ない!」をご覧ください
「参照型」はクラス(class) や配列です。
インターフェース(interface) やデリゲート(delegate) も参照型になります。
値型の変数は値そのものを格納するのに対して、
参照型の変数は実体がある場所(アドレス)を格納するという違いがあるのですが、
この2つの違いを正しく理解する事はとても重要です。
変数がメモリ上でどのように管理されるか
値型である構造体と、参照型であるクラスで似たようなコードを作ってみました。
それぞれの変数がメモリ上でどのように管理されているかを見てみましょう。
値型(構造体)
public struct Point
{
public int x;
public int y;
}
public static void Main(string[] args)
{
Point p1;
Point p2;
p1.x = 1;
p1.y = 2;
p2 = p1;
}
10~11行目で2つの変数が作られました。
以下はメモリ空間のイメージです。

値型の変数は値そのものを格納するので
p1.x・p1.y・p2.x・p2.y を格納する領域が
スタックメモリという場所に割り当てられます。
↓
↓
16行目で代入が行われています。

p1 の x・y の値がそれぞれ p2 にコピーされます。
参照型(クラス)
public class Point
{
public int x;
public int y;
}
public static void Main(string[] args)
{
Point p1;
Point p2;
p1 = new Point();
p1.x = 1;
p1.y = 2;
p2 = p1;
}
10~11行目で2つの変数が作られました。
以下はメモリ空間のイメージです。
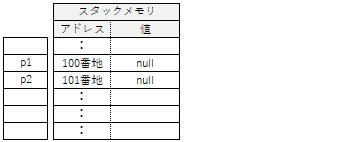
参照型は実体の参照先アドレスを格納するので、
p1とp2という2つのアドレス格納用の領域が
スタックメモリという場所に割り当てられます。
但し、この時点ではまだ実体がありません。
↓
13行目で new をしています。
実体を作る作業(インスタンス生成)です。
ここで Point の x・y を格納する領域が
ヒープメモリという場所に割り当てられ、
そのアドレスが変数 p1 の値に記録されます。

↓
16行目で代入が行われています。
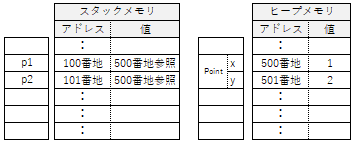
参照型はアドレスがコピーされるだけです。
p1 も p2 も同じ x・y を参照する事になります。
代入の違いに注意
値型と参照型がどのようにメモリ上で管理されているかが分かれば、代入した時の動きの違いが分かるはずです。
値型(構造体)
public struct Point
{
public int x;
public int y;
}
public static void Main(string[] args)
{
Point p1;
Point p2;
p1.x = 1;
p1.y = 2;
p2 = p1;
p2.x = 5;
Console.WriteLine("p1.x=" + p1.x + " p1.y=" + p1.y);
Console.WriteLine("p2.x=" + p2.x + " p2.y=" + p2.y);
}
p1 を p2 に代入した後、p2.x の値を書き換えています。
値型は p1 を p2 それぞれが x・y の格納場所を持っているので結果は以下のように p1 と p2 は異なります。
p1.x=1 p1.y=2 p2.x=5 p2.y=2
参照型(クラス)
public class Point
{
public int x;
public int y;
}
public static void Main(string[] args)
{
Point p1;
Point p2;
p1 = new Point();
p1.x = 1;
p1.y = 2;
p2 = p1;
p2.x = 5;
Console.WriteLine("p1.x=" + p1.x + " p1.y=" + p1.y);
Console.WriteLine("p2.x=" + p2.x + " p2.y=" + p2.y);
}
p1 を p2 に代入した後、p2.x の値を書き換えています。
18行目の代入は本体の x を値を書き換えます。
p1 と p2 は同じアドレスを参照しているので結果は以下のように同じものになります。
p1.x=5 p1.y=2 p2.x=5 p2.y=2
メソッドの引数に注意
メソッドの引数に渡す場合にも、上記の代入と同じような事が起こります。
値型(構造体)
public struct Point
{
public int x;
public int y;
}
public static void TestProc(Point prm)
{
prm.x = 8;
}
public static void Main(string[] args)
{
Point p;
p.x = 1;
p.y = 2;
TestProc(p);
Console.WriteLine("p.x=" + p.x + " p.y=" + p.y);
}
11行目でTestProc メソッドへ p が渡されます。
この時 prm という変数がメモリ上に確保され
p の内容(xとy)が prm にコピーされるという事が行われます。
コピーされた prm.x の値が変更されたとしても、
コピー元の p.x に変化はありません。
p.x=1 p.y=2
参照型(クラス)
public class Point
{
public int x;
public int y;
}
public static void TestProc(Point prm)
{
prm.x = 8;
}
public static void Main(string[] args)
{
Point p;
p = new Point();
p.x = 1;
p.y = 2;
TestProc(p);
Console.WriteLine("p.x=" + p.x + " p.y=" + p.y);
}
11行目でTestProc メソッドへ p が渡されます。
この時 prm という変数がメモリ上に確保され
p の内容(アドレス)が prm がコピーされるという事が行われます。
prm も p と同じ本体を参照しているので、
prm.x を変更すれば p.x も変わります。
p.x=8 p1.y=2
それぞれのメリット・デメリット
変数へ値を格納するという部分だけ見ると、参照型では「変数の作成」→「インスタンスの作成」という2段階のステップが必要となり処理コストがわずかですが大きい事が分かります。
しかしメソッドの引数に渡す場合などは、新たに変数が作られ値がコピーされて利用されます。
仮に構造体が数キロバイトもある巨大なものだったとしたら、そのすべてをコピーする作業は大変な処理コストになると予想できます。
(参照型であればアドレスを格納する為のわずかなサイズの変数をコピーするだけで済みます)
int や double のような小さなサイズのデータであれば値型の方が都合がよく、
文字列や配列のような大きなサイズのデータでれば参照型の方が都合がよいというわけです。
関連記事
- C#の値型と参照型の違い
- C#のコンストラクタでオーバーロード
- C#のコンストラクタの継承
- C#のジェネリックを使おう
- C#のデリゲート (delegate) って何?
- C#のデリゲートお手軽にする匿名メソッド
- C#のラムダ式【=>】って何?
- C#で基底クラスのメソッドを置き換えるオーバーライド
- C#でキャストとas演算子を使いこなす
- C#で型を判別するtypeofとis演算子
- C#の値型でもnullを扱えるようにするNullable
- C#のリソース解放にはIDisposableとusingを使おう
- C#のStringとstring、Int32とint 違いは・・・ない!
- C#でasync/awaitを使った非同期処理
- C#で文字列を指定の区切り文字で分割
- C#のstring.Formatで桁数や書式を指定する
- C#の配列やListをソートする
- C#の配列やListを検索する (Find,FindAll,FindIndex)
- C#の配列やListを高速に検索する (BinarySearch)
- C#の配列の中に指定の要素が存在するかを調べる(LINQ Contains)
- C#の配列の中に条件を満たす要素が存在するかを調べる(LINQ Any)
- C#の配列から条件に合う要素を抽出する(LINQ Where)
- C#の配列で要素毎の処理結果を得る(LINQ Select)
- C#の配列を並び替える(LINQ OrderBy,ThenBy)
- C#の配列をグループ毎に処理する(LINQ GroupBy)
- C#の配列を内部結合(INNER JOIN)する(LINQ Join)
- C#の配列から最初の要素を取り出す(LINQ First,FirstOrDefault)
- C#の配列の重複要素を削除する(LINQ Distinct)
- C#でフォルダ内のファイル名一覧を取得する
- C#でテキストファイルを読み込む
- C#でテキストファイルに書き込む
- C#でバイナリファイルを読み込む
- C#でバイナリファイルに書き込む
コメントをお書きください